Research Overview
Multifunctional Integrated Circuits and Systems Group (MICS)
BRain Inspired Computing & Circuits (BRICC) Lab @ MICS
Yang (Cindy) Yi, Ph.D., is a tenured Associate Professor in the Bradley Department of Electrical and Computer Engineering (ECE) at Virginia Tech (VT). Her research is primarily focused on Very Large Scale Integrated (VLSI) Circuit and Systems, Neuromorphic Computing, Congitive Computing and Communications, Emerging Technologies, Hardware Reliability and Variability. Her major accomplishments include designing and fabricating analog neural chips for spiking recurrent neural network, designing and analyzing the energy-efficient circuits for green computing and communication system, and exploring the application of recurrent neural network and machine learning to wireless communications and cybersecurity. Her research has been funded by National Science Foundation (NSF), Department of Defense (DoD), NSF Experimental Program to Stimulate Competitive Research (EPSCoR), Air Force Office of Scientific Research (AFSOR), Air Force Research Lab (AFRL), and Industrial companies. Some of her current research projects are listed as follows:
In our one-of-a-kind lab, we conduct joint research in the hardware and software domains of Brain-Inspired Computing and Circuits, ranging from low-level Memristors to high level algorithms for Spiking Neural Networks, with applications in the Wireless Communication domain and more!
This particular research setting enables us not only to theoretically contribute to Neuromorphic Computing, but also tightly couple and evaulate the algorithms on our specialized neuromorphic hardware. This greatly aids in getting the brain-inspired AI technologies closer to real-world deployment with applications in a variety of domains. Thank you for taking interest in our research; take a look below on what, why, and how we do research in our lab, and if enthusiastically intrigued, feel free to contact Dr. Yang (Cindy) Yi.
Encoders and ASIC Design


AI chips are specialized hardware components designed to perform artificial intelligence tasks more efficiently than traditional processors. They are engineered to handle the complex computational needs of AI models and algorithms and are used in a variety of applications, including autonomous vehicles, computer vision, natural language processing, and more.
Some of the things that AI chips can do:
- Accelerate machine learning: AI chips are optimized for performing the types of computations required for training and inference in machine learning models. This can greatly speed up the process of developing and deploying AI applications.
- Improve energy efficiency: Traditional processors can consume a lot of power when performing AI tasks. AI chips, on the other hand, are designed to be much more energy-efficient, making them ideal for use in devices with limited power resources, such as mobile phones and drones.
- Handle large amounts of data: AI models require large amounts of data to be trained effectively. AI chips are capable of processing huge amounts of data in parallel, making them well-suited for handling the big data requirements of AI.
- Enable real-time processing: Many AI applications require real-time processing, such as self-driving cars that need to react to changing road conditions. AI chips can perform computations quickly enough to enable real-time processing, which is critical in many use cases.
- Support diverse AI workloads: AI chips can be optimized for specific types of AI workloads, such as computer vision or natural language processing. This allows them to perform these tasks much more efficiently than traditional processors.

Overall, AI chips are an important component in the development and deployment of artificial intelligence applications. By providing faster, more efficient, and more specialized processing capabilities, they enable the development of more powerful and sophisticated AI systems.
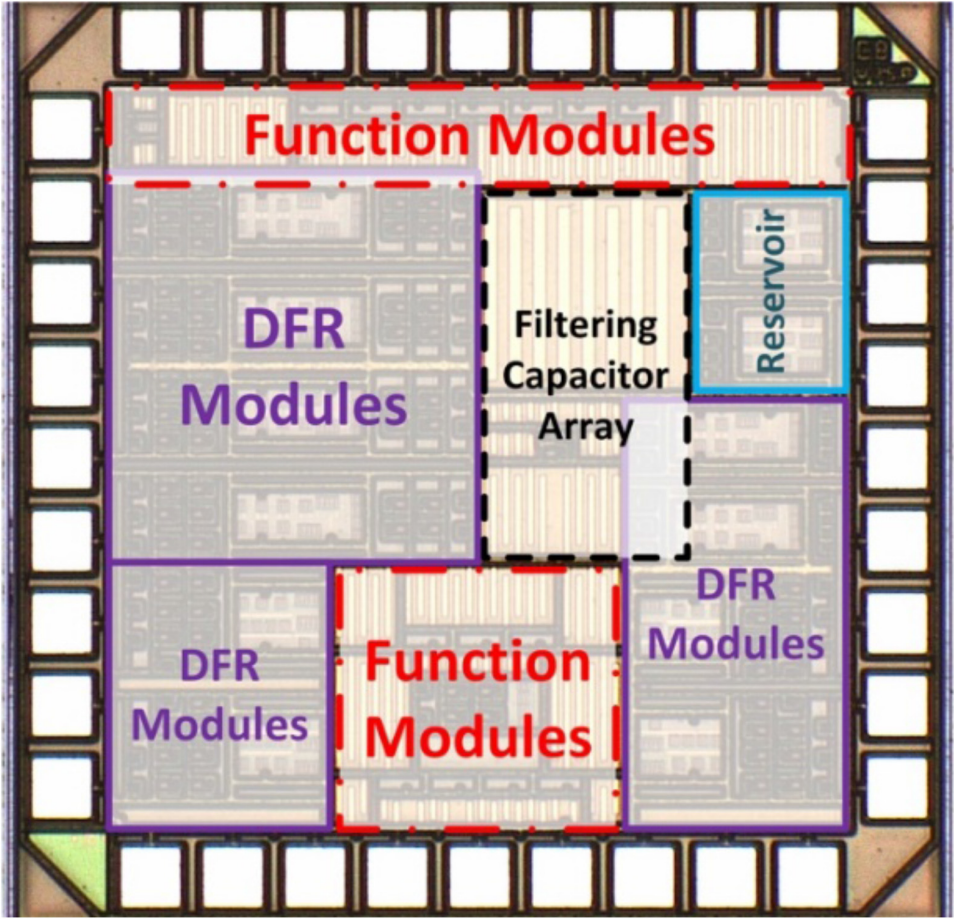
Our group has designed and fabricated many different components and types of AI chips, including spatial-temporal neural encoder, delay feedback reservoir (DFR) neural network, and spatial-temporal hybrid neural network (STHNN), as shown in the figures. The spatial-temporal is able to extract both spatial and temporal information from the input signal and transfer them into spike signals. The DFR is proven to have a similar performance to the classic reservoir computing system while having a much simpler structure in the reservoir layer. The STHNN is able to utilize both spatial information and temporal information in the same neural network to achieve high classification accuracy
Memristors-based Neuromorphic Computing
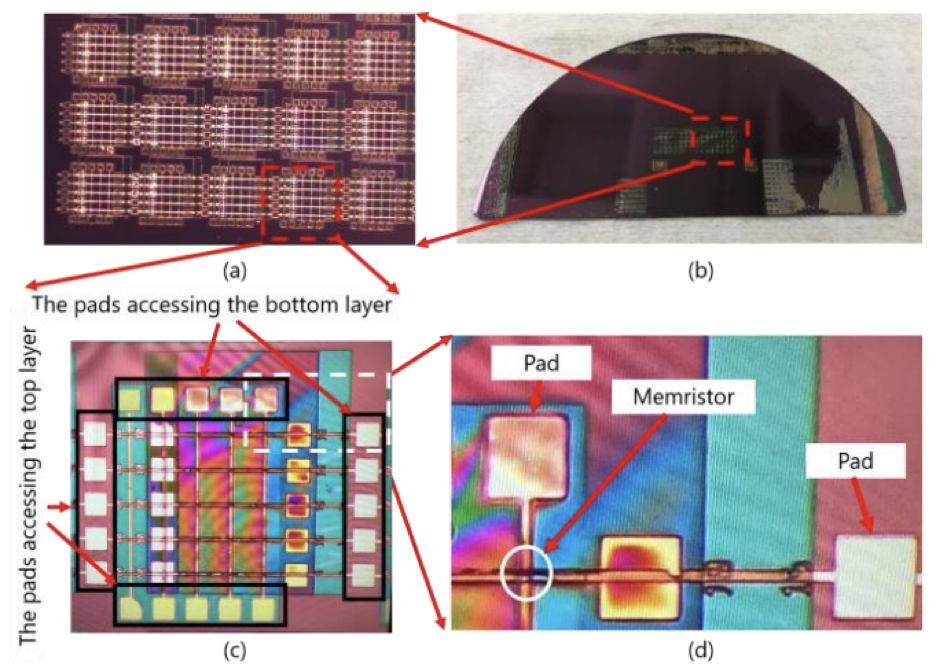
The data-intensive nature of AI applications makes them computationally inefficient to run on traditional computing architectures. Due to the large number of vector-matrix multiplication operations in the Neural Networks, a significant amount of power is spent on data movement - to and from the memory. This is a latent limitation of von-Neumann Architecture, on which a majority of conventional computing-hardware is based. The latency of this data movement between the computing/processing unit and the memory also limits the throughput performance of the system.
A Memristor crossbar can solve this issue of increased energy consumption and latency by carrying out large amounts of vector-matrix multiplication operations in-memory. As an emerging non-volatile memory (eNVM) technology, the memristor has gained immense popularity in recent years due to their ability to emulate spiking neurons and synapses to aid in the making of neuromorphic hardware. With the use of our two-layer fabricated VT memristor, we aim to develop energy-efficient Neuromorphic Computing architectures. Our work encompasses memristor-based Spiking Neural Networks, spiking Reservoir Computing, as well as in-memory computing architectures.
Algorithms for Spiking Neural Networks and Loihi
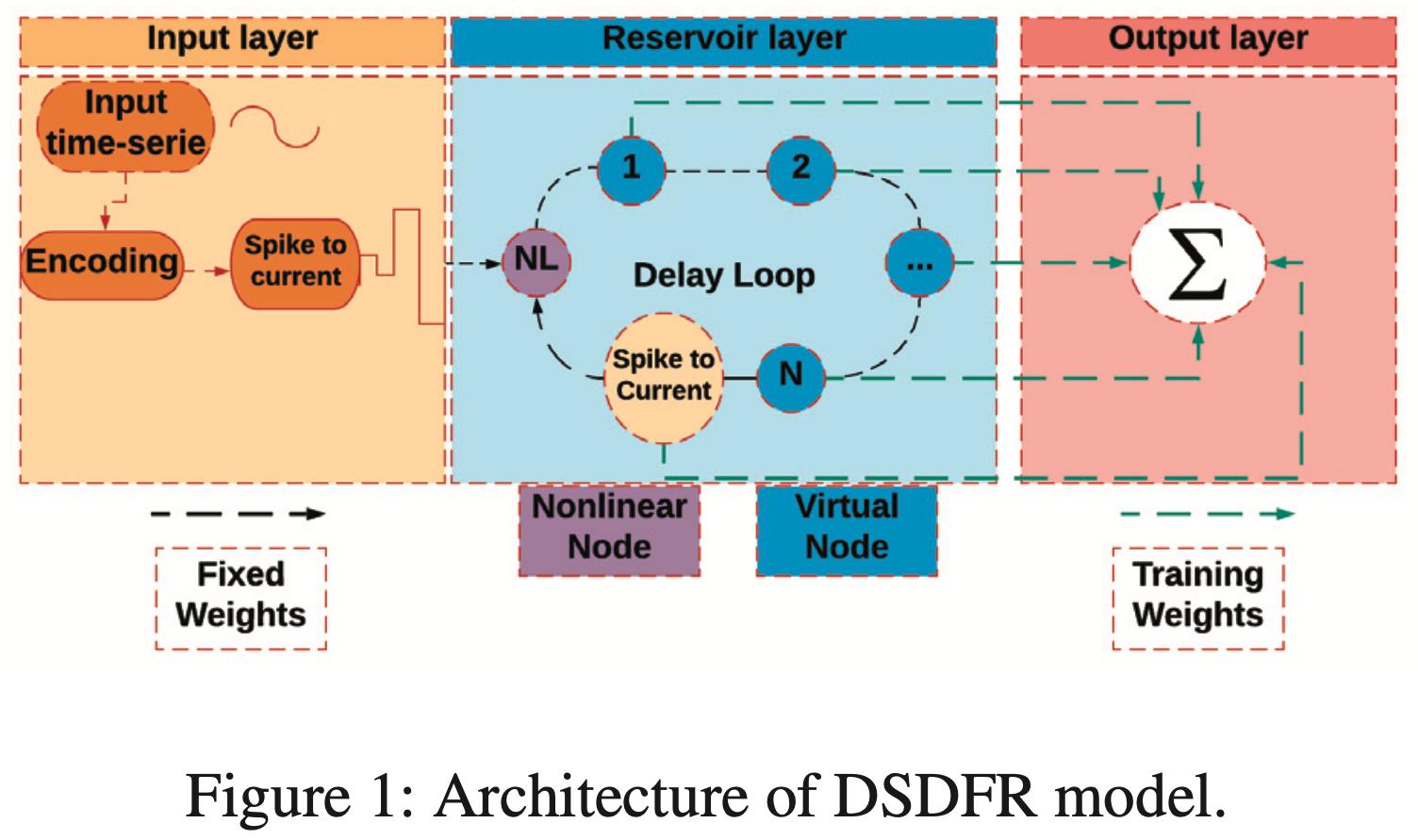
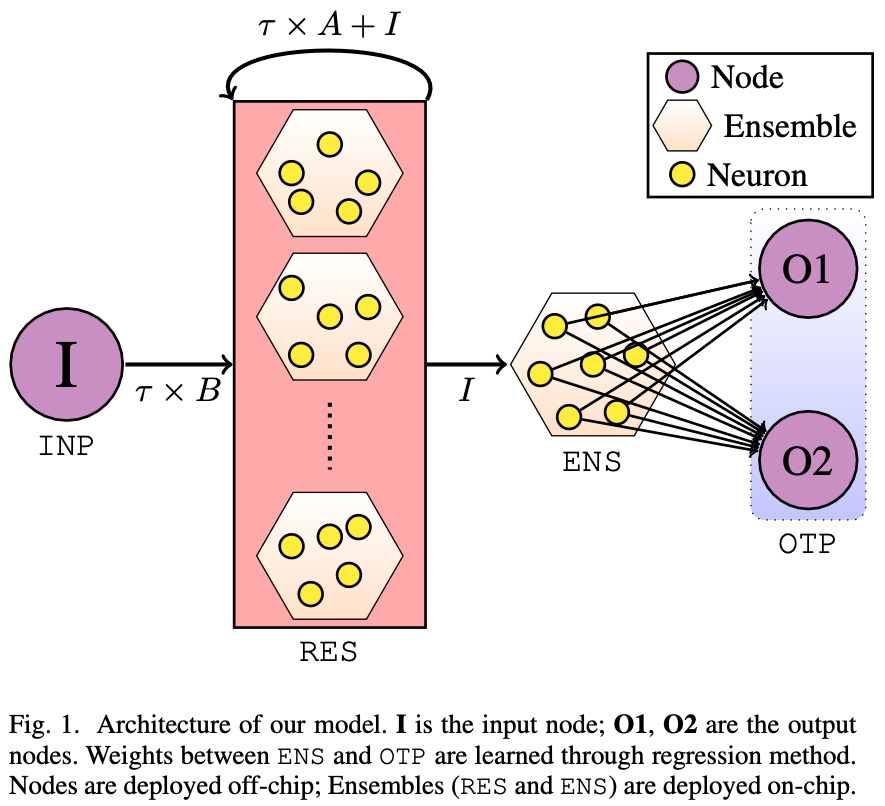
One of crucial aspects of information processing in our brain is the generation and transmission of action potentials, a.k.a. spikes. Spiking Neural Networks (SNNs) are the next generation Neural Networks which employ spiking neurons to accomplish general AI tasks. Unlike the Artificial Neural Networks (ANNs), they are inherently temporal in nature, with few works advocating SNNs to be more robust and potentially more powerful than ANNs!
So far, in our attempts to develop brain-like AI, we have been working with the conventional ANNs for long (since the start of 1940s), which are composed of highly abstracted out non-spiking neurons. The recent breakthroughs in AI can be largely attributed to the coupling of effective ANN training techniques and suitable hardwares e.g. GPUs/TPUs. But this has come at the cost of high energy consumption while training and inferencing; this is not at all scalable for edge devices or battery powered critical AI systems. SNNs on the other hand, in conjunction with specialized neuromorphic hardware e.g. SpiNNaker, Loihi, TrueNorth, etc. offer the promise of low-power and low-latency AI!
In this lab, we actively work in the field of Neuromorphic Computing to develop spiking network algorithms with a focus on their deployability on specialized neuromorphic hardware, e.g., Intel’s Loihi. We also collaborate with other (hardware) teams in this lab to develop novel neuromorphic hardware customized spiking networks for applications in wireless communication domain, apart from the general AI tasks.
Neuromorphic Computing in Communications



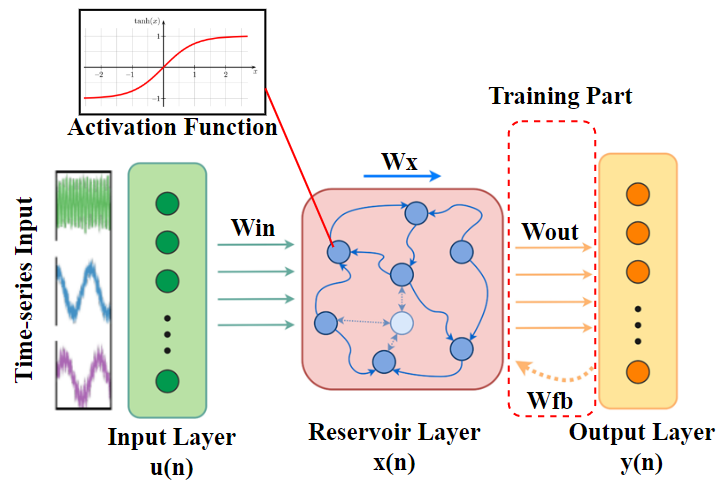
Brain-Inspired computing, such as Reservoir Computing, provides a new paradigm of data-driven algorithm design for communication systems. The rich dynamics behavior of Reservoir Computing may help build simplified signal detection algorithms using efficient training techniques.
Future communication systems, such as the 5G/6H wireless networks, face many new design and implementation challenges. For example, traditional model-based algorithms may not scale well with massive MIMO antenna systems and have model mismatch problems in real-world environments. Furthermore, their high complexity hinders power efficiency for mobile and IoT applications.
We have adopted Echo State Networks (ESN) and demonstrated their superior performance in a real-time Software-Defined Radio (SDR) testbed. Our ESN-based MIMO-OFDM symbol detection system is more resilient and power efficient than conventional algorithms widely used in the current 5G systems. We are also exploring other types of Neuromorphic Computing techniques for applications in wireless systems.
Neuromorphic Computing and FPGA
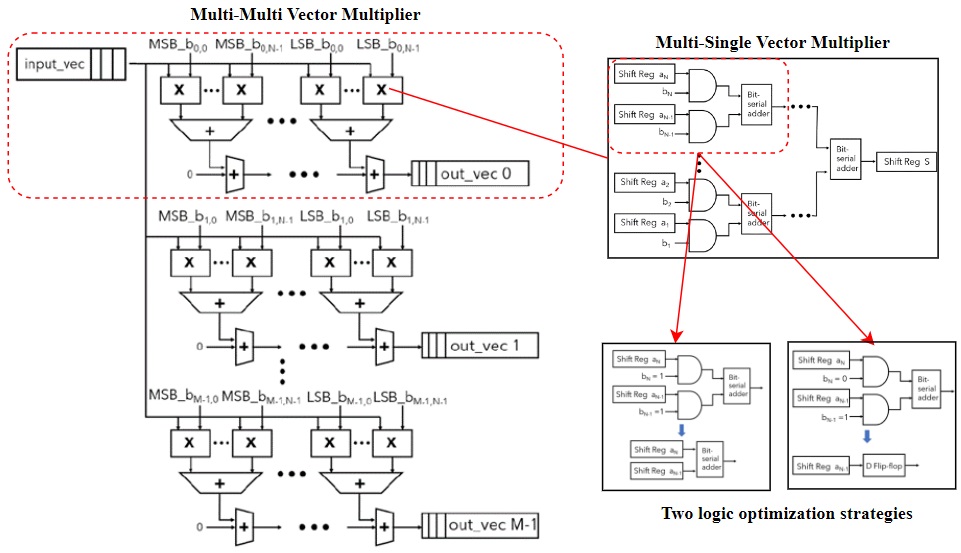

Neuromorphic Computing is based on the non-von Newman architecture, which breaks the memory bottleneck of the traditional computing chips to achieve low-power, low-cost, and low-latency design. FPGA-based Neuromorphic Computing design focuses on the hardware implementations of neuromorphic computing systems and architectures on FPGA and the associated optimizations on it.
Due to the novel architecture of neuromorphic computing, it has better computation efficiency on temporal tasks than traditional Neural Networks such as Recurrent Neural Networks (RNNs). However, neuromorphic computing chips such as Intel’s Loihi, are still not mature enough to implement all kinds of circuits. Many ideas about the architectural optimizations on the neuromorphic computing systems need to be verified in time, which is easily doable on FPGAs - a reconfigurable and mature platform for circuit design.
We have been working on new architectural designs of the typical models of recurrent networks such as, Echo State Network (ESN), Delayed Feedback Reservoir (DFR), etc., adapting them to neuromorphic systems with their designs implemented and verified on the FPGA platforms.
Table of Contents
Sponsors and Collaborators
-

National Science Foundation (NSF) 
Air Force Office of Scientific Research (AFSOR)
Air Force Research Lab (AFRL)-

NSF EPSCoR -

Intel Corporation -

Texas Instruments Inc. -

Alphabet Inc (Google) -

Samsung Research America -

NVidia Inc.